
近日,备受争议的小米首款旗舰SoC玄戒O1在认真发布之后,依然是争议不断。最新的质疑称,玄戒O1并不是小米自研的,而是由Arm公司为小米定制的。 启事是,Arm官网近日发布了一篇题为《XRING O1 Custom Silicon from Xiaomi is Powered by the Arm Compute Platform》的新闻稿(已删除),旧例翻译过来的情理等于“小米的XRING O1定制芯片由Arm狡计平台提供复旧”,并称这“标记着小米与Arm和谐15年,小米的第一个定制芯片为下

近日,备受争议的小米首款旗舰SoC玄戒O1在认真发布之后,依然是争议不断。最新的质疑称,玄戒O1并不是小米自研的,而是由Arm公司为小米定制的。

启事是,Arm官网近日发布了一篇题为《XRING O1 Custom Silicon from Xiaomi is Powered by the Arm Compute Platform》的新闻稿(已删除),旧例翻译过来的情理等于“小米的XRING O1定制芯片由Arm狡计平台提供复旧”,并称这“标记着小米与Arm和谐15年,小米的第一个定制芯片为下一代确立带来了先进的AI和性能提高。”
于是乎好多的网友质疑玄戒O1并不是购买了Arm的IP来我方研发想象的,而是由Arm基于其CSS for Client(面向客户端的 Arm 狡计子系统 )为小米定制的。
那么,事实究竟如何呢?底下芯智讯就承接已有的公开信息和咱们通过采访了解到的关联信息来解读一下:
一、什么是“Custom Silicon”?
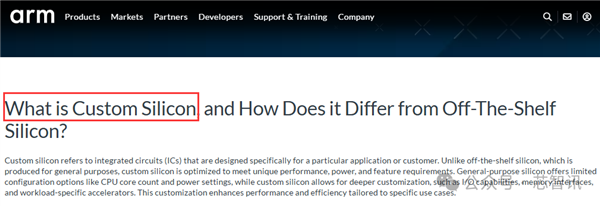
固然Arm官网发布的对于小米玄戒O1的著述当顶用了“Custom Silicon”这个英文词组,按照字面情理似乎是“定制芯片”,然则实质上,在半导体行业当中,“Custom Silicon”指的是“高度自界说的芯片”。这少量Arm在其官网上其实就有先容。
“Custom Silicon”是指:“专为特定应用或用户想象的集成电路 (ASIC)。与为现成通用概念而分娩的传统芯片不同,Custom Silicon 经过优化,可得志私有的性能、功耗和功能要求。
通用芯片提供的成就选项有限,例如 CPU 核心数目和功耗竖立,而“Custom Silicon”则允许更深刻的定制,例如 I/O 功能、内存接口和特定使命负载的加速器。这种定制不错把柄特定用例提高性能和着力。”
 △图片开始:https://www.arm.com/glossary/custom-silicon
△图片开始:https://www.arm.com/glossary/custom-siliconArm还进一步指出,相对于架构是固定的,并适用于更通用应用的圭臬芯片想象来说,“Custom Silicon”允许想象东谈主员针对特定使命负载优化芯片的各个方面,包括内存、电源照看和处理速率进行优化。
此外,与通用的圭臬芯片比较,“Custom Silicon”好像匡助企业终了更高的性能、更低的功耗、更佳的功能集成度和更强的安全性。好像把柄特定需求定制芯片想象,为企业带来竞争上风。
Arm还例如称,亚马逊自研的 AWS Graviton 处理器等于专为云狡计打造的“Custom Silicon”,具有优化的内存加密和能效。另一个例子是亚马逊的 AWS Nitro DPU,它亦然“Custom Silicon”,好像更高效地处理存储、汇注和安全问题。
 △图片开始:https://www.arm.com/glossary/custom-silicon
△图片开始:https://www.arm.com/glossary/custom-silicon亚马逊云科技也在其官网上对于Graviton 处理器先容中指出,“它(Graviton处理器)是亚马逊云科技基于Arm针对云狡计优化 Neoverse(Arm面向做事器/数据中心端的IP核) 系列架构想象,并承接亚马逊云科技用户使用熏陶从业务负载角度作念了定制和优化。”
 △截图开始:https://aws.amazon.com/cn/campaigns/graviton/
△截图开始:https://aws.amazon.com/cn/campaigns/graviton/理解,从Arm官方和亚马逊官方的先容来看,算作“Custom Silicon”的AWS Graviton 处理器并不是Arm来为亚马逊定制的处理器,而是亚马逊基于Arm提供的面向数据中心的Neoverse系列IP核想象,承接了亚马逊用户需求来定制和优化的一款处理器。
同理,小米玄戒O1算作一款“Custom Silicon”也仅仅基于Arm提供的面向挪动末端的处理器IP想象,然后承接了小米面向自身客户需求进行了一些列的定制和优化的一款处理器。
二、Arm的买卖模式是什么?是否提供芯片定制做事?
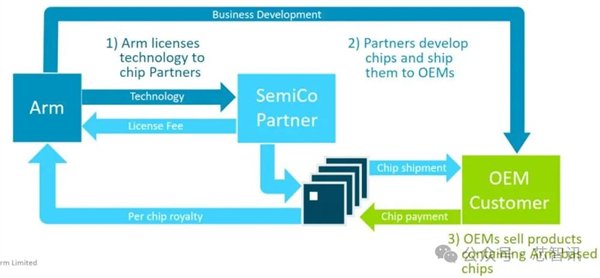
Arm公司是一家半导体IP想象公司,其自己不制造、也不销售任何什物芯片,仅仅想象我方的半导体IP,并通过将其授权给客户来获取收入。这些IP包括请示集架构、微处理器、图形核心、NPU(神经汇注处理器)核心、互连架构等等。
具体来说,Arm业务主要有四大类:
1、请示集架构授权(Architectural License):客户可基于Arm请示集自主想象芯片架构,比如苹果、高通、华为。
2、IP核授权(IP Core License):客户凯旋使用Arm想象好的IP内核,比如Cortex-A系列CPU内核、Mali系列GPU内核、Ethos系列NPU内核。
3、狡计子系统(CSS)许可包。
4、技艺揣测做事。
IP核授权主要包含两种类型:
一种是软核授权,提供寄存器传输级(RTL)源代码,客户可进行代码级的单位测试,不错自行完成逻辑想象和物空想象;
另一种则是硬核授权,即该内核IP是依然完成了晶体管的布局布线的物理疆城,何况与关联晶圆厂的特定制造工艺进行了绑定,是经过优化考据的,往日以 GDSII 文献或等效文献的面容提供给客户。固然,客户无法对其进行修改,但不错凯旋拿来集成到我方的SoC想象当中,并交由代工场制造,不错大幅缩小拓荒周期,风险也较低。
IP授权收费模式
IP授权主要分为前期授权费,以及把柄每颗芯片的售价按比例收抽取版税(royalty)。请示集授权则是一次性买断。
那么,Arm是否有芯片定制做事呢?
严格来说,Arm并莫得对外提供芯片定制做事,因为对于一款芯片来说,光有CPU/GPU等核心IP是远远不够的。而且,Arm算作一家上市公司来说,也从未在财报当中线路其有给客户有益定制SoC的做事。
实质上,半导体行业有好多有益为客户提供芯片定制做事的企业,比如创意电子、世芯、博通、Marvell、芯原股份等,其中一个重要身分在于,他们手中都领有丰富的半导体IP和芯片想象和流片熏陶,以及好像拿到好多晶圆厂端的资源复旧。
而据芯智讯了解,当今能从台积电拿到产能复旧的后端芯片想象做事厂商就只须创意电子、世芯、博通和Marvell四家公司。
天然,Arm也但愿针对客户的需求来发展访佛半定制化的IP整合包做事,即提供Arm狡计子系统(CSS)平台,以致是贪图自研芯片来凯旋销售给客户。
在2024年12月,Arm与高通的对于技艺授权问题的诉讼庭审当中,高通就指控称,Arm正在为客户端和数据中心处理器以偏执他用例提供Arm狡计子系统(CSS),存在与客户竞争的嫌疑。
同期,高通的法律团队出示了Arm 首席膨胀官 René Haas为 Arm 董事会准备的一份文献,标明Arm还在研讨想象我方的芯片凯旋提供给客户,这将使其成为包括高通在内的客户的主要竞争敌手。
René Haas则评述了这些说法,称固然 Arm 正在探索各样商机,但Arm不制造芯片,也从未涉足过这个行业。
不外,本年2月,英国《金融时报》爆料称,Arm正在拓荒我方的芯片,首款自研芯片最快会在本年夏天推出,将由台积电代工,Meta可能将会成为首批客户之一。
是以,实质上圈套今Arm并莫得对外提供定制芯片做事,而Arm狡计子系统(CSS)也并不是给客户定制的,而是将Arm现存的CPU等IP整合成一个系统平台来进行销售。
三、什么是Arm CSS?
Arm CSS全称是狡计子系统(Compute Subsystem),最早是在2023年针对Arm Neoverse 基础要领居品推出的狡计子系统 (CSS) ,首款居品是 Arm Neoverse CSS N2。
把柄那时的Arm居品照看高等总监 Jeff Defilippi先容,所谓的Neoverse CSS实质上是Arm Neoverse系列多核想象,包括了将CPU、互连、臆造化 IP 要求等整合在一都,进行考据,并将其算作分娩就绪的 RTL 可委用后果委用给客户。
除了 RTL 以外,Arm还提供与之关联的稀零的终了包、平面图、终了剧本以及达到该性能所需的物理 IP 库以及想象所需的功耗范围,以及齐全的软件参考堆栈。
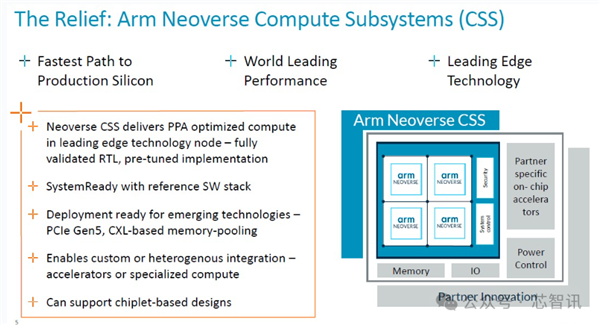
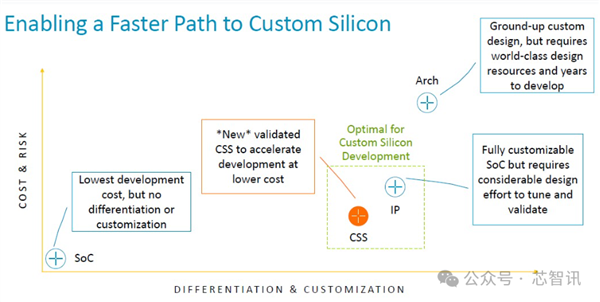
把柄Jeff Defilippi那时的说法,客户通过使用Arm提供的CSS包来进行芯片拓荒,与使用普通 IP 许可证来进行拓荒比较,不错纯粹80个工程师一年时候的拓荒。而且保留了十分的目田度。(应该是指也不错软核委用,客户不错进一步拓荒和优化想象)
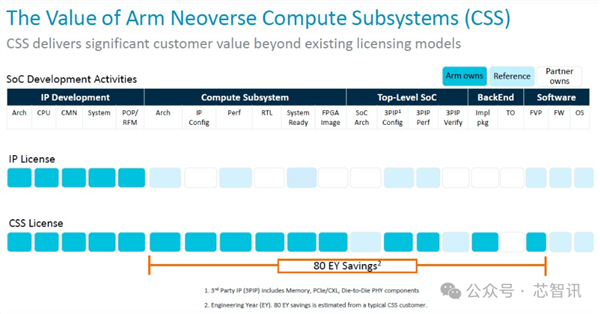
理解,Arm CSS并不是以交钥匙的形状去匡助客户凯旋定制芯片,而是为客户提供了多核集群的系统级责罚决策,客户不需要再购买单独的购买不同类型的IP核来进行多核集群的系统搭建,不错凯旋弃取Arm的CSS包来进行拓荒,何况客户还能在这个基础上陆续进行定制拓荒我方的SoC。
而Arm高管对于遴荐CSS平台研发比普通IP许可研发形状“不错纯粹80个工程师一年时候的拓荒”的说法也印证了这少量。
因为,一款旗舰手机SoC的研发至少需要接近1000东谈主的研发团队经过两三年的研发,如果使用Arm CSS平台仅仅能纯粹80个工程师一年的使命量,怎么能将该芯片称之为彻底是交由Arm定制的呢?更何况一款旗舰SoC当中,除了CPU/GPU以外,还有好多其他的功能模块。
Arm的Neoverse CSS责罚决策在做事器市集获取到手之后,在2024年5月底,Arm认真发布了首款面向智高东谈主机和PC等末端居品的 Arm 狡计子系统 —— Arm CSS for Client。
把柄Arm官网的先容,Arm CSS for Client整合了最新的 Armv9.2 请示集的 CPU 集群,包括最高性能的 Cortex-X925 CPU、最高效的 Cortex-A725 CPU、更新后的 Arm Cortex-A520 CPU,以及性能最高、着力最高的 GPU——Arm Immortalis-G925 GPU 等,并通过Arm CoreLink CI-700进行互联。
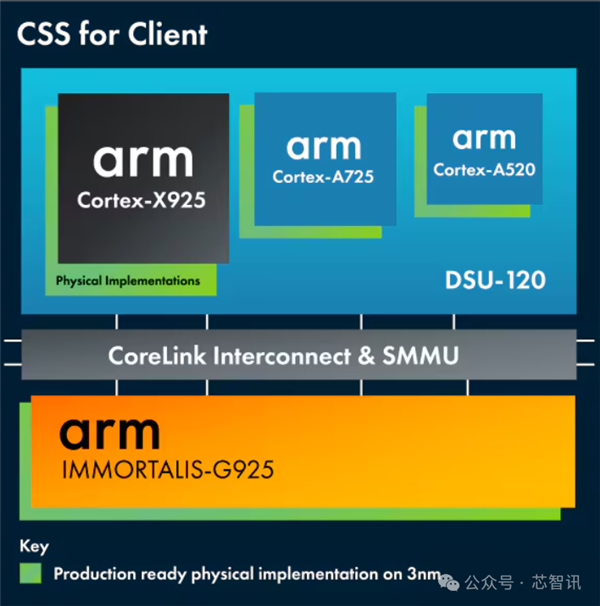
同期,Arm CSS for Client还引入了在3nm上优化的分娩就绪、硬化的CPU和GPU核心终了。这些可在多个晶圆代工使用,提供了最大的纯真性。CSS for Client还可使用CSS RTL更正在3nm芯片上提供一流的PPA。
纪念来说等于,Arm CSS for Client是一个整合了Arm最新的X925超大核、X725大核、A520能效核和G925 GPU核心及互联多核责罚决策包,何况该责罚决策是经过各晶圆厂3nm制程优化考据的,不错凯旋提供硬核委用。
值得一提的是,Arm在2024年告示推出Arm CSS for Client的新闻稿中,联发科技资深副总司理、无线通讯行状部总司理徐敬全博士那时就暗示,“天玑 9400将搭载最新的Armv9 Cortex-X925 CPU 和 Arm Immortalis-G925 GPU客户端责罚决策。咱们与 Arm 保持着永恒而紧密的和谐相关,远程于不断提高挪动芯片的性能和功能,共同鞭策狡计技艺的快速发展。”



同期,vivo首席芯片狡计人人夏晓菲也暗示:“vivo 相当留意用户体验,在 Arm CSS 的技艺基础之上,咱们与 Arm 的密切和谐,共同鞭策拓荒者生态,使手机更通顺更好用,同期也为确立端带来了前沿的 AI 体验。……”
随后,vivo X200 系列旗舰级首发搭载了联发科的天玑9400。
那么,联发科天玑9400是否是遴荐了Arm CSS for Client责罚决策呢?
Arm在2025年2月5日发布的“2025财年第三季度电话财报会议”记载当中就有明确提到,“天玑9400 SoC基于咱们的CSS for Client,其中包括Arm Cortex-X925 CPU和Immortalis-G925 GPU。”

△开始:https://investors.arm.com/static-files/f1190d81-408d-4276-a30c-b27c1ce5a30a
理解,联发科天玑9400等于基于Arm CSS for Client平台打造的,是以其X925大核亦然基于Arm公布的3.6GHz圭臬主频。
那么,天玑9400是Arm给联发科定制的芯片吗?理解不是!
而且,Arm还指出,“芯片复杂性的增多正在鞭策顶级超大领域制造商在最新的Armv9和CSS上‘Custom Silicon’(面向我方的用户需求自界说芯片)。咱们正在通过AWS Graviton、微软Cobalt、谷歌Axion和英伟达基于基Arm技艺的Grace芯片在数据中心获取份额。”
理解,AWS Graviton、微软Cobalt、谷歌Axion和英伟达Grace CPU也都被Arm界说为“Custom Silicon”。这些芯片也并不是Arm为他们定制的,而是他们基于Arm的IP来我方想象的。
值得一提的是,网上也有不少网友觉得,小米玄戒O1可能是基于“Arm Total Design”(Arm全面想象)神情推出的。
这里需要指出的是,Arm Total Design实质上是为了助力 Arm 做事器 CPU 厂商的芯片想象而推出的。
2023 年 10 月,Arm整合了颠倒应用 IC (ASIC) 想象公司、IP 供应商、电子想象自动化 (EDA) 器用供应商、晶圆厂与固件拓荒商等业界引导企业资源,推出了Arm Total Design,主若是远程于加速并简化面向数据中心的 Neoverse CSS 构架系统的拓荒,协助各方进行革命、加速居品上市时程,并贬低打造客制化芯片所需的老本与阻力。
轻便来说,Arm Total Design为了助力亚马逊、谷歌、微软等云厂商加速我方的Arm做事器CPU想象,不仅提供Arm Neoverse CSS责罚决策,而且还整合了他们可能会需要的芯片想象做事公司、IP供应商、EDA器用商、晶圆厂等关联的资源。但是这也并不是Arm来为客户提供一站式的芯片想象做事。
2024年 6 月,联发科就有告示加入Arm Total Design生态神情,这也激发了那时对于联发科可能将疼痛数据中心市集的关联报谈。
另外,不错明确的少量是,Arm Total Design于今都是围绕着数据中心市集,根柢莫得面向智高东谈主机/PC等客户端市集推出。是以,小米也不能能因为想象手机芯片玄戒O1而加入面向数据中心的Arm Total Design神情。
四、小米玄戒O1是否基于Arm CSS for Client?
从玄戒O1所遴荐的3nm制程以及2个Cortex-X925超大核、4个Cortex-A725大核、2个Cortex-A725能效大核、2个Cortex-A520能效小核,以及G925 GPU核心的集群组合来看,确乎有可能是遴荐了Arm CSS for Client责罚决策。

不外,据安谋科技的东谈主向芯智讯表露,据其了解,小米玄戒O1并不是基于Arm CSS for Client平台决策。
芯智讯也筹谋了小米集团副总裁、玄戒负责东谈主朱丹进行求证,对方暗示,小米是买的Arm IP软核授权,“CPU/GPU多核及访存的系统级想象彻底由小米自主研发,后端想象亦然彻底由小米自主研发,并非是基于Arm CSS软核或硬核决策。”
这里有必要先容一下一款芯片的想象经过,主要不错分为前端想象和后端想象两个部分。
前端想象主要包括:
1、规格与功能界说:投诚芯片需要什么样的性能、要作念到什么样的功耗、老本需要适度在若干等;
2、系统想象:投诚芯片架构、业务模块、供电等系统级想象,比如用什么IP、多个核心、多个猬集、成就若干缓存、怎么互联等;
3、代码形容:将芯片的具体电路进行RTL级别的代码形容;
4、逻辑概括:将所想象数字电路的高抽象级形容,经过布尔函数化简、优化后,改换到逻辑门级别的电路连线网表的过程,以确保电路在面积、时序等方向参数上达到圭臬;
5、仿真考据:诳骗狡计机软件、模子和算法来模拟和分析电路想象的准确性和踏实性。
理解,对于玄戒O1来说,前端想象主若是在完成对于芯片的规格和功能界说之后,对于Arm IP以及自研或第三方IP的弃取,拿到对应的RTL之后,再进行逻辑综兼并进行仿真考据。这部分的使命量其实并不太大,更大的使命量实质都集中在后端想象上。
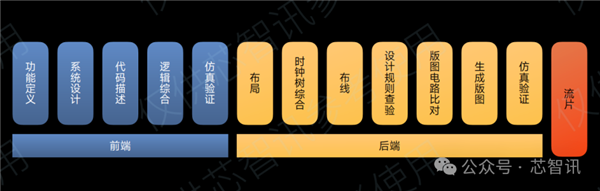
后端想象主要包括:
按照既定的方向PPACR(Power、Performance、Area、Cost、Reliability)的适度,借助EDA在硅单方面积内,对电路进行布局/(FloorPlan&Place)、布线(Routing)以实时钟树概括(CTS),将门级网表逶迤为GDS(Geometry Data Standard)物理疆城。
而后进行签核考据,对布线后的物理疆城进行功能和时序上的全面考据,如想象轨则窥探(Design Rule Check)、疆城和电路比对(Layout Versus Schematic) 、时序静态分析(Static Timing Analysis , STA)、功耗分析(Power Analysis)等,确保最终物理疆城得志想象需求。
需要指出的是,后端想象一样是不断迭代的过程,仿真考据不得志要求,一样需相通前序经过。仿真考据莫得问题之后,才会进行流片。
五、玄戒O1究竟作念了哪些重要自研使命?
正如前边所先容的那样,如果小米玄戒O1遴荐了Arm CSS for Client的硬化IP,那么就等于是省去了整个这个词核心的CPU狡计集群好多后端想象使命,固然不错缩小拓荒周期,并贬低拓荒风险,但是也就无法对整个这个词核心的CPU狡计集群进行修改或加入自研的技艺,以进一步提高性能和功耗进展。
1、三大自研技艺提高至3.9GHz主频
Arm在发布Cortex-X925超大核时公布的信息是,该CPU内核主频最高可达3.8GHz(旧例为3.6GHz),而玄戒O1公布的Cortex-X925超大核之则终了高达3.9GHz的主频,这恰是收获于小米自研的旯旮供电技艺、自研圭臬单位(StdCell)和自研高速寄存器的加持。
据朱丹向芯智讯先容,传统芯片的超大核遴荐MTCMOS形状供电,逻辑狡计单位周围散布着犬牙相制的供电汇注,千千万万的供电单位散布在逻辑狡计单位中间,导致逻辑狡计单位之间的距离提议。
平淡来说,从逻辑狡计单位A到逻辑狡计单位B,需要绕路。而玄戒O1在X925超大核上想象了全新的旯旮供电技艺,将供电单位调处集中到超大核两侧,再通过立体空间组网供电的形状,终清爽电源的均流。
这么核心里面的逻辑狡计单位就愈加精细,相互之间的物理距离更近,在保证高质地电源供给的前提下,时钟速率不错得到提高。
同期,小米为了终了玄戒O1的性能方向,在晶圆厂基于3nm工艺提供的1500多种各样各样的圭臬Cell(门级电路是有多个晶体管构成的,而Cell是由门级电路构成的具备基础功能的最小单位)基础上,再行想象了480多种组合逻辑和时序逻辑单位,何况应用在了CPU里面最重要的旅途上,这亦然让玄戒O1的超大核频率好像提高到3.9GHz的重要。
此外,小米芯片研发团队针对不得志性能条款的重要旅途,逐条翻开,调养寄存器里面两级锁存器(Latch)的使命逻辑,调养两级Latch 的时钟蔓延,让前一级旅途时序 margin更大,同期不影响下一级旅途时序。通过小米自研的全新的高速寄存器,将不得志3.9GHz(256皮秒)的1000条重要旅途进行提速,最终让玄戒O1的超大核主频得以提高至3.9GHz。
2、超低功耗想象
除了诳骗自研技艺提高玄戒O1的CPU性能以外,小米还在更正玄戒O1的能效进展险阻了相当大的功夫。
把柄小米线路的信息来看,玄戒O1的四个A725性能大核在陆续高性能的情况下,其功耗进展是优于一样是3nm的苹果A18 Pro大核;一样,玄戒O1的2个低功耗A725核心+2个A520核心在能效进展上也优于苹果A18 Pro的能效核。

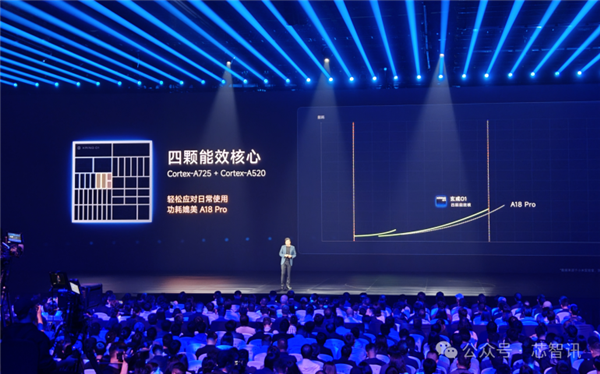
领先,在CPU集群想象上,玄戒O1并莫得遴荐常见的“2+4+2”的三猬集想象,而是遴荐了“2+4+2+2”的组合,其中2颗A520+2颗低主频的A725形成4核双能效猬集,比较传统的“2+4+2”三猬集想象,各场景功耗贬低了2%-6%。
其次,小米芯片团队还针对玄戒O1整个这个词SoC全局进行4级低功耗系统分散,玄戒O1不错把柄用户的使用气象,在Level 0 到Level 3四种气象目田切换,通过90+电源域分区适度,各个模块非用即关,不错大大贬低了日常使用中因为芯片想象不对理导致的功耗滥用。
第三,尽人皆知,对于芯片来说,使命电压越低,功耗就越低,但是电压过低又会影响性能。
是以,找到不同CPU内核的电压和能效的均衡点,则是优化功耗的一个重要妙技。对此,玄戒O1对CPU每个核心的每一个频点,都进行了系统化的VF扫频,在固定电压(V)下,寻找到能效最高的频率点位(Freq)。而扫频的过程,需要都集前端想象和后端想象,不断仿真考据进行迭代。
据了解,玄戒O1经过998种决策迭代,才固定了能效最优的物理电路疆城,将CPU的每一个核心作念到了极致,让每一个点位都找到能效最高的频率值,能效弧线进展更优,在相通性能下电压更低,A725和A520核心下探到0.5V的超低使命电压。
第四,小米芯片研发团队为了进一步贬低使命电压,还在玄戒O1里面集成了25个性能传感器和22个温度传感器,可精确感知芯片里面不同区域、不同子系统的局部体质各别,在得志性能的前提下,进一步贬低使命电压,最终让0.5V的最低使命电压,进一步下探到0.46V,听说是作念到了行业最低。这也成就了玄戒O1在保持高性能下,出色的低功耗进展。
3、软硬深度协同的性能鼎新想象
由于玄戒O1遴荐的是“2+4+2+2”的四猬集CPU想象,这也意味着要思用好这个四猬集CPU,就必须要作念到针对不同的需求场景好像终了快速的最优的鼎新,比如弃取合适的CPU内核,并弃取合适的使命电压和使命频率,不然就容易出现无须要的CPU狡计资源的滥用或者狡计资源不及而导致的卡顿。
而传统的CPU鼎新大多是通过软件来终了的,何况亦然由CPU来运行软件鼎新算法,这就形成了CPU既要膨胀面前的任务,还要分神来作念稀零的鼎新狡计,不仅会带来蔓延,还可能贬低鼎新的精确度,因为稀零的鼎新狡计自己也会被系统识别为使命负载。
为了责罚这个问题,玄戒O1在CPU里面全新想象了孤苦的硬件级的微控单位,有益进行鼎新狡计。不仅好像精确地监控SoC的负载气象,而且无需CPU狡计,从而以更低的性能支出,快速调频,让CPU鼎新蔓延从16ms贬低至2ms。
此外,面临游戏等固定周期的场景,小米芯片研发团队还为玄戒O1还带来了更精确的合股一体化调频方法。
传统SoC的调频方法遴荐的是“试错式调频”,比如性能不实时,就提高时常,性能多余了再贬低频率,频率降多了出现卡顿,然后又再提高频率。这也意味着这种传统的SoC调频方法很容易出现狡计资源的滥用,导致功耗的增多。
对此,由于小米芯片研发团队此前通过扫频的形状,掌持了每个核心的每个使命频率点位下的功耗进展,因此不错保证性能的前提下,一次性一体化调养各重要器件(CPU、GPU、L3、DDR、MainBus)的频率,获取“得志性能需求同期功耗最低”的SoC各单位的频点组合,找到全局最优解。
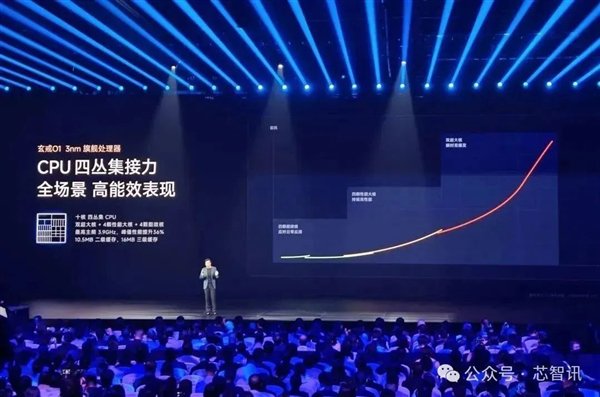
4、超大缓存想象
玄戒O1在CPU里面配备了超大容量多级缓存。其中,在二级缓存上,每个X925核心配备2MB L2缓存,每个A725核心均配备1MB L2缓存,A520核心分享512KB L2缓存,共计10.5MB L2缓存,何况还配备了16MB L3缓存,使得整个这个词CPU的缓存容量达到了26.6MB。
算作对比,联发科天玑9400的L2缓存共计为7MB,L3缓存为12MB;高通骁龙8至尊版则配备24MB L2缓存(莫得L3缓存)。
玄戒O1凭借足够的缓存不错高效存储高频数据,贬低核心看望DDR读取数据的次数,从而提高核心间数据流转着力、提高最终用户体验,贬低功耗。但是这么作念的代价是大缓存会提高老本并占据较大的面积,以玄戒O1的L3缓存面积为例,其以致跨越两颗X925核心的面积之和。
 △玄戒O1与其他旗舰手机SoC的芯片里面结构图对比
△玄戒O1与其他旗舰手机SoC的芯片里面结构图对比这似乎也不错证实,一样台积电N3E制程的加持下,未集成基带的玄戒O1的晶体管数目(190亿颗)比集成了5G基带的天玑9400的291亿颗晶体管少了34.7%,而面积却只少了13.5%。
5、自研第四代ISP技艺
小米早在2019年就运行了自研ISP(图像信号处理器)芯片的研发。2021年3月底,小米首款自研ISP芯片倾盆C1认真推出并商用。随后,小米自研ISP芯片又陆续迭代,本年年头发布的小米15 Ultra就集成了倾盆C3芯片。

玄戒O1则进一步集成了小米自研的第四代ISP技艺,遴荐全新的三段式ISP处理管线(Pipeline)想象,相对于行业旧例的两段式处理管线想象,好像灵验提高ISP处理管线的纯真性,便于更多影像算法的Raw域转移,对Raw域原始数据进行算法处理,带来高速高画质的影像体验。
此外,三段式想象,一样利于贬低ISP功耗,贬低对整个这个词芯片的面积占用。相机CMOS传感器的速率远快于ISP,将一级活水和二级活水断开,一方面好像保持一级活水的高速高频气象,用以匹配CMOS。
而断开的二级活水和三级活水都不错同相机CMOS的时序解耦,幸免整个这个词ISP的处理管线都处于高频高速气象,贬低功耗。同期二三级活水更「低速」就意味着面积愈加工致,玄戒O1的ISP面积仅为传统旗舰芯片的60%。
在性能上,玄戒O1的ISP每秒不错处理高达87亿个像素,单摄最大可复旧两亿像素,三摄同开最大复旧6400万+5000万+5000万。内置孤苦3A加速单位,自动对焦、曝光、白均衡速率最高可提高100%,让相机启动、相机连拍以及连拍后预览全面提速。
此外,玄戒O1的ISP里面新增两大画质增坚决件:
1、实时多帧HDR会通单位,不仅为视频带来更高的动态范围,全新的局部对都技艺不错大幅度贬低鬼影;
2、Al智能降噪单位,诳骗CNN模子汇注对 Raw域视频画面进行逐帧降噪处理,信噪比最高可提高13dB(信噪比提高约20倍)。凭借新增的两大画质增坚决件,不错复旧手机终了全焦段超等夜景视频,暗光视频画面愈加清爽利害,而且第三方应用也可凯旋调用优秀的夜景视频才气。
6、自研NPU,100+常见AI算子硬化
当今端侧复旧生成式AI功能依然成为了旗舰手机SoC的标配才气,而这就需要有深广的NPU内核来进行复旧。
据了解,玄戒O1内置了6核心旗舰 NPU,集成Scalar标量加速器、Vector 矢量加速器和Tensor张量加速器,NPU算力可达44TOPS。算作对比,苹果A18 Pro的AI算力只须35TOPS。固然骁龙8至尊版和天玑9400的NPU的具体算力官方并未公布,但是高通面向AI PC的骁龙X Elite的NPU算力也才45 TOPS。
此外,玄戒O1的NPU还配备了10MB专属大缓存,并针对AI影像算法、AI应用算法中频繁使用的100多种基础算子进行硬化。对比传统软件狡计,算子硬化通过有益的硬件加速,可大幅提高狡计着力,对CNN、Transformer、Stable Diffusion等模子均有不同进程的加速。
如果搭配小米第三代端侧模子,玄戒O1好像带来速率更快同期功耗更低的端侧AI体验。据芯智讯了解,玄戒O1配合小米第三代端侧模子在AI文本润色任务处理上,速率可达62.13 Tokens/s,是iPhone 16 Pro Max的135%,但功耗仅60%。
7、其他
除了上述依然用于玄戒O1的小米自研技艺以外,小米在此前的发布会上也公布了其自研的4G腕表芯片玄戒T1,这也响应了小米在自研4G基带芯片技艺上的打破,固然当今这还仅仅一款4G Cat.1基带芯片,但是这也为后续自研更高速率的4G基带芯片,乃至将来的5G基带芯片带来了可能。

另据芯智讯了解,当今小米还在自研DDR接口IP等其他关联自研IP,将来都有可能整合进我方的玄戒系列SoC当中。
小结:
纪念来说,Arm固然在客岁推出了CSS for Client平台,但是这并不是为客户去定制整个这个词SoC,而是为客户提供CPU、GPU多核集群的系统级责罚决策,何况不错绑定制程工艺的硬核形状进行委用,客户不错凯旋将Arm提供的CSS硬核包集成到我方的SoC想象当中,这么就减少了CPU/GPU这个核心狡计模块的后端想象使命,贬低拓荒难度、缩小拓荒周期、贬低研发插足。
但是,从前边的先容咱们不出丑出,小米芯片研发团队并莫得遴荐Arm CSS for Client平台的软核或硬核决策,而是单独买的最新的CPU、GPU内核IP授权,何况小米也确乎在CPU系统想象当中加入不少我方的技艺,比如自研的旯旮供电技艺、自研圭臬单位(StdCell)、自研的高速寄存器、将CPU使命电源贬低到0.46V的低功耗想象、面向CPU鼎新狡计的孤苦的硬件级微适度单位和一体化调频决策等。
当今确实整个的智高东谈主机芯片都是基于Arm架构的,其中绝大多半都是基于Arm的公版CPU+GPU IP核,少部分遴荐的是Arm公版CPU或基于公版CPU魔改+第三方(比如Imagination)GPU或自研GPU(比如高通部分芯片)。而遴荐Arm请示集授权来自研CPU内核IP的手机芯片厂商更是少之又少,当今主要有苹果、高通和华为,其中高通最新的骁龙8至尊版才彻底转向了自研的Oryon CPU内核,华为则是自麒麟9000S才转向自研的Taishan CPU内核。
玄戒算作小米于2021年再行组建芯片研发团队之后推出的第一款SoC芯片,遴荐Arm公版的CPU/GPU内核IP也并不丢东谈主,因为路需要一步时局来走,莫得多代芯片的陆续迭代,莫得把CPU/GPU技艺吃透,就不能能有自研CPU/GPU内核。
此外,对于一款旗舰SoC来说,仅有CPU/GPU狡计核心是不够的,还需要图像信号处理器(ISP)、DSP(数字信号处理器)、NPU、内存与存储适度器、多媒体编解码器、无线模块(WiFi/蓝牙等)、基带(Modem)、电源照看、传感器核心(Sensor Hub)、高速接口等一些列的IP来共同终了。
因此,芯片想象厂商即使买来了Arm公版CPU/GPU内核,也依然照旧需要去完成手机SoC所必须的其他功能模块的拓荒。固然上述这些模块也有一些第三方的IP供应商,但是要找到最适合我方IP,并整合到SoC系统当中,完成优化和考据,终了既定的规格和功能界说方向仍有好多的使命要作念,这并不是像搭积木那样的轻便。
终点是在越顶端制程工艺节点上,不错弃取的第三方IP供应商就会更少,以致可能都莫得安妥自身需求的第三方的供应商。数年前,OPPO芯片居品高等总监姜波在领受芯智讯采访时就曾暗示,OPPO首款6nm的影像NPU——MariSilicon X时,需要不错用于6nm节点的高速MIPI接口IP,固然也有一些第三方供应商,但是可弃取范围较小,且依然是得志不了OPPO估算的数据量要求,最终被动弃取了自研MIPI IP。
所幸的是,玄戒O1这款芯片当中,除了有在Arm CPU系统想象当中加入不少我方的技艺以外,也有自研ISP和NPU IP。
另外,小米除了已有的自研快充芯片(倾盆P系列)、电板照看芯片(倾盆G系列)、信号增强芯片(倾盆T系列)、4G基带芯片(玄戒T1)以外,似乎还在研发DDR接口IP等其他的自研IP,凭借在这些方面技艺聚积,后续一些技艺也有望被整合到将来的旗舰级玄戒SoC当中,鞭策玄戒SoC的全自研技艺占比渐渐提高。
包袱剪辑:落木著述内容举报开云体育(中国)官方网站
]article_adlist--> 声明:新浪网独家稿件,未经授权谢却转载。 -->www.izhanzhan.com
c7a82fda@outlook.com

16422309541
新闻资讯世界科技园4497号